After many searches, I ended up using this one:
http://monocleglobe.wordpress.com/2010/01/12/everybody-needs-a-little-printf-in-their-javascript/
pretty nice
After many searches, I ended up using this one:
http://monocleglobe.wordpress.com/2010/01/12/everybody-needs-a-little-printf-in-their-javascript/
pretty nice
In Mac you can always type ‘open filename’ to open a particular type of file or a folder. In Linux (Fedora I am using) similar command is xdg-open.
My first-hand experience so far (been here exactly 1 year):
1. Slow in response (email, in person)
2. Slow in action (e.g. It took 3 days to change a directory permission so I could read it)
3. Incapable managers
3. Never know how to read emails (immediate reply asks questions which was clearly answered in my last email)
4. Global distribution of teams. (no accountability. they can totally disappear for days without making any progress. and when they come back, no.3 happens)
Be default function keys of apple keyboard serve as multimedia keys (media control, volume up/down) without fn key. But these F1,F2,… keys are more often used during coding/debugging rather than media control. To change them back to F1,F2.. see following post:
https://www.dalemacartney.com/2013/06/14/changing-the-default-function-key-behaviour-in-fedora/
Disclaimer: people have done this a million times but I just wanted to see it myself.
One of the merits of node.js that people keep talking about is it scales really well under the pressure when there’s a large number of users using the service at the same time. Let’s examine the validity of this witness today:
I’ve built a small website using Node.js + sqlite, with some in-house caching. For the testing request, there are 4 SQL Select requests. The database file is fairly light-weighted with less than 1 million records and the queried columns are indexed as well. But in theory all this shouldn’t matter as long as the same url has been visited, all those DB results are cached and no more DB access is needed.
I used ‘ab’ for concurrent tests and below is the result:
concurrency = 1 to 100
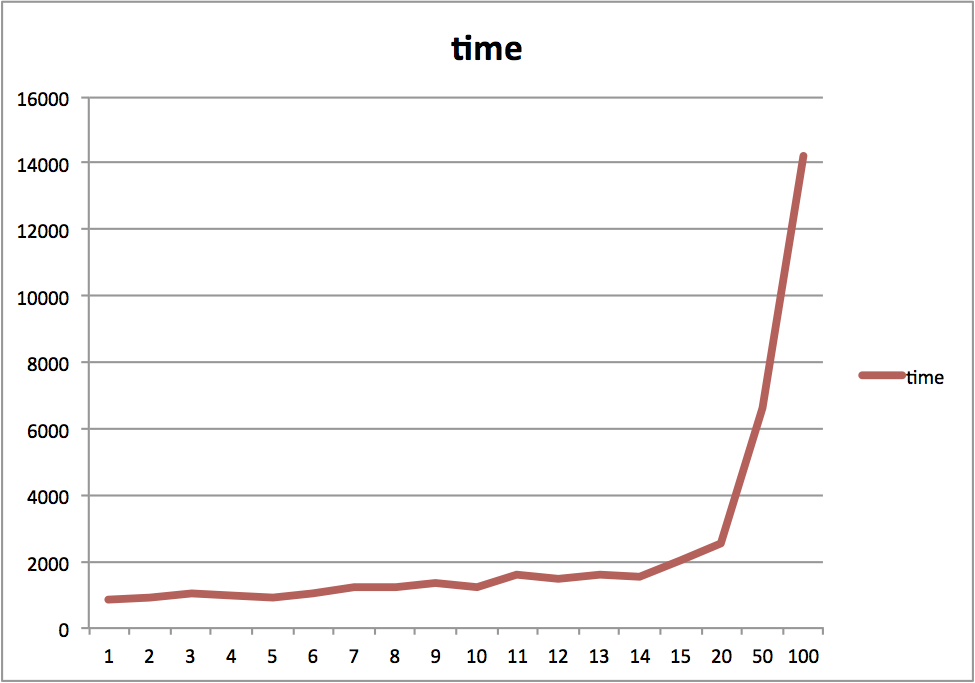
#request from 100 to 1000
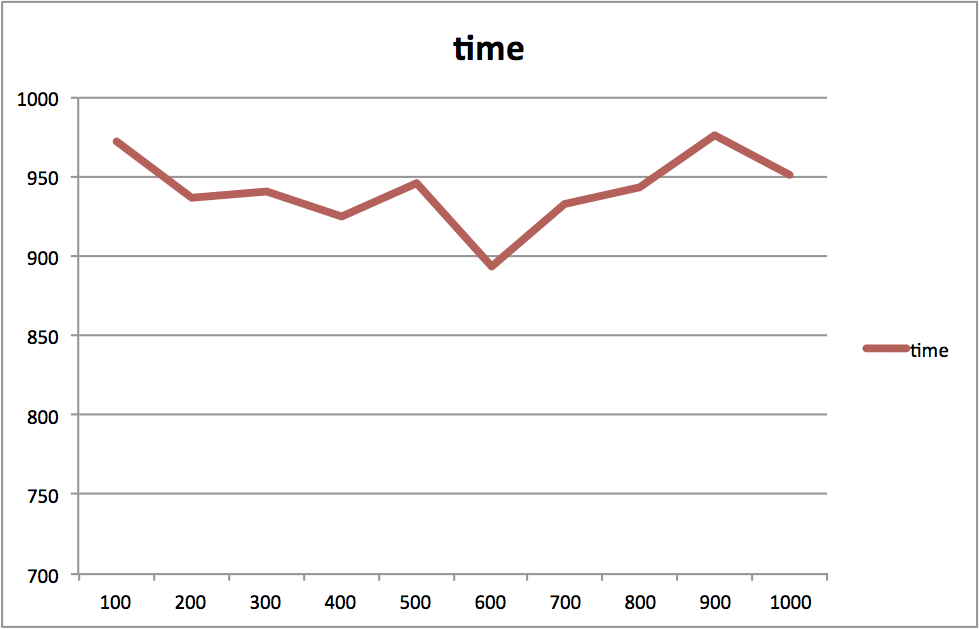
Apparently node.js handles multiple requests pretty well until concurrency exceeds 15 for my hardware
some good read at:
http://perfectionkills.com/whats-wrong-with-extending-the-dom/
This usually happens when we asynchronously operate on a large number of files in Node.js and due to the async nature of Node.js many files are open at the same time. See explanation at https://stackoverflow.com/questions/16200497/emfile-error-in-async-file-reading
Two solutions: 1) use sync version of readFile. so each file is closed before proceeding to next 2) use callback function for reading next file, something like
function readFile(files, i) {
if(i>=files.length) return;
fs.readFile(path+'/'+files[i], 'utf8', function (err,data) {
if (err) {
return console.log(err);
}
parse(data, function(result){
readFile(files,i+1);
});
});
}
fs.readdir(path, function(err, files) {
readFile(files,0);
});
We often get this error when trying to allow directory browsing. The error log file says:
” pcfg_openfile: unable to check htaccess file, ensure it is readable”.
I following this https://stackoverflow.com/questions/13921529/apache-error-when-setting-up-silex-bootstrap-unable-to-check-htaccess-file and got it fixed!
We are given some data, and we want to apply some machine learning do it (classification, clustering, etc.) To do that we need to load data to NumPy’s arrays.
I browsed through NumPy’s examples and APIs and, while there are batch loading methods (load whole file into an array), there’s no method to appending a row just like Python’s built-in list does. Why?
Because NumPy’s after efficiency and performance. But to dynamically allocate space and move data around is very time-consuming. So NumPy allocates all the space beforehand.
Scipy: You can try ‘yum install’. But I dont know where the installed lib went and I cant import it in my python script. Had to install from source.
You need a fortran compiler. I used yum and installed gfortran44.
Then install BLAS. So far this one been helpful: https://stackoverflow.com/questions/7496547/python-scipy-needs-blas
On 64-bit env, dont forget to add -fPIC -m64 to make.inc to fortan’s opts.
to run build Scipy, run ‘python setup.py build’. If it complained about not finding fortran compiler, do a symbolic link to your favorite fortran compiler. e.g. sudo lnk -s /usr/bin/gfortran44 /usr/bin/gfortran then I was able to finish compiling
This link may also be helpful: http://bickson.blogspot.com/2011/02/installing-blaslapackitpp-on-amaon-ec2.html
